Implementing a Fast Attention Fusion Kernel

Table of Contents
Writing Fast Attention on TPU — From Naive Kernel to Fused FlashAttention with Pallas
Part 1 of the KernelForge series on writing, profiling, and optimizing custom TPU kernels in Python.
Part 2: Mastering TPU Performance Profiling
Part 3: The Ratchet Loop — Systematically Optimizing a TPU Kernel to the Hardware Ceiling
Google Cloud credits are provided for this project.
If you’ve worked with transformers, you already know the bottleneck: self-attention. For a sequence of length $n$ and head dimension $d$, the textbook implementation computes $\text{softmax}(QK^T / \sqrt{d}) \cdot V$ and materializes an $n \times n$ attention matrix along the way. At a sequence length of 16,384 — pretty standard for modern LLMs — that single matrix eats over 1 GB of memory in float32. For one head.
JAX’s XLA compiler is genuinely impressive at optimizing most operations. But when it comes to attention at long sequences, there’s a massive gap between what XLA produces and what the hardware can actually deliver. The compiler has no idea you could skip writing that giant attention matrix to memory entirely. That insight — which underpins FlashAttention — is something you have to implement yourself.
That’s exactly what we’ll do here. We’ll start from why Pallas exists, build up an intuition for the TPU hardware we’re targeting, derive the FlashAttention algorithm step by step, and then write a working fused kernel. Along the way, I’ll run concrete fusion experiments so we can see the impact of each optimization — no hand-waving, just numbers.
All the code lives in the kernelforge repository: a three-file harness designed for iterative kernel work. It gives you an immutable benchmark judge (prepare.py), a mutable kernel workspace (kernel.py), and an append-only results log. Every experiment is reproducible and every number you see here is real.
1. Why Pallas?
JAX compiles your Python into XLA HLO (High-Level Operations), and XLA’s backend lowers that into hardware-specific instructions. For most things — matmuls, convolutions, pointwise math — XLA does a fantastic job. But when you need fused or memory-aware operations, XLA’s optimizer hits a wall. It optimizes individual ops in isolation; it can’t see the bigger picture of how they fit together.
That’s where Pallas comes in. It’s JAX’s kernel-authoring extension — think of it as an escape hatch. When XLA’s auto-generated code isn’t cutting it, you drop down one level and tell the hardware exactly what to do. You write Python functions that operate on small tiles of data in fast on-chip memory, and Pallas handles the plumbing of shuttling data between slow off-chip memory and your fast scratchpad.
Here’s what makes it tick:
- Target hardware: TPUs (via the Mosaic compiler) and GPUs (via Triton).
- Programming model: Tile-based — you define block shapes, and your kernel runs once per tile.
- Pipelining: Pallas automatically double-buffers data transfers so compute and memory access overlap.
2. TPU Architecture: The Minimum Viable Mental Model
Before we write a single line of kernel code, we need a working mental model of the hardware. Here’s the minimum — nothing more, nothing less.
2.1 The Memory Hierarchy
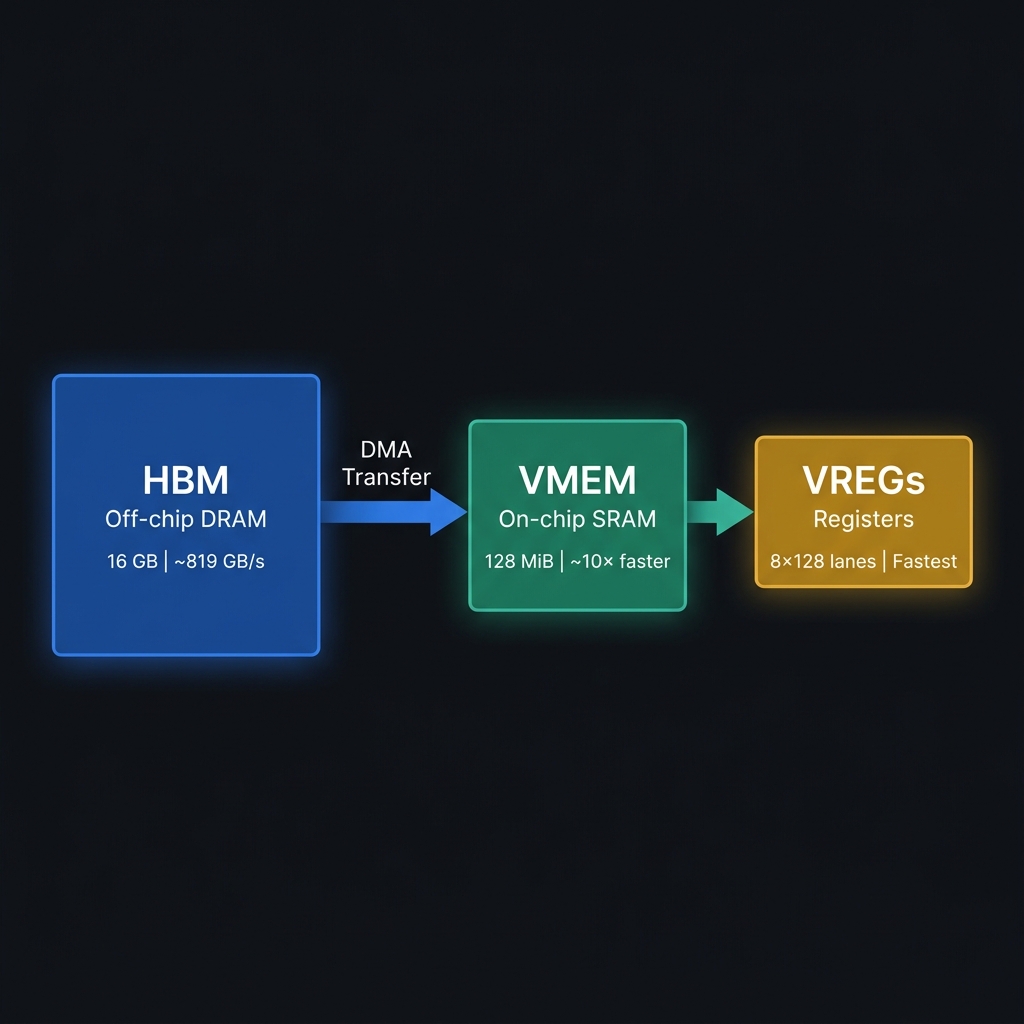
| Level | What it is | TPU v5e size | Speed |
|---|---|---|---|
| HBM | High Bandwidth Memory. Where full tensors (Q, K, V, O) live. | 16 GB | ~819 GB/s bandwidth |
| VMEM | Vector Memory. On-chip SRAM scratchpad inside the TensorCore. Where Pallas tiles live during compute. | 128 MiB | ~10× faster than HBM |
| VREGs | Vector Registers. Where computation actually happens. Laid out as 8 sublanes × 128 lanes. | Small | Fastest |
The key constraint here is simple: VMEM is fast but tiny. Your block sizes — including double-buffered copies and any scratch buffers — have to fit within that 128 MiB budget. Go over, and the Pallas compiler will either refuse to compile outright (VMEM overflow) or silently “spill” registers to VMEM, which tanks your performance.
2.2 Compute Units
| Unit | Purpose | Key fact |
|---|---|---|
| MXU (Matrix Multiply Unit) | Dense matrix multiplication | 128×128 systolic array. Performs bf16 × bf16 → f32 accumulation natively. Peak: 197 TFLOP/s on v5e. |
| VPU (Vector Processing Unit) | Elementwise ops: add, mul, exp, max, comparisons, casts | Operates on vector registers. exp is medium cost; reductions over the last array dimension are the slowest path. |
| Scalar Unit | Control flow, loop indices, conditions | Used for grid orchestration — the pl.program_id() calls. |
The MXU deserves a bit more explanation because it’s where the magic happens. It’s a systolic array: weights get loaded into a grid of processing elements and stay put, while activation data streams through row-by-row. Each of the 16,384 processing elements does one multiply-accumulate per cycle. That’s incredible parallelism — but the array needs to be saturated (inputs should be multiples of 128 in both dimensions) to hit peak utilization. Feed it undersized tiles and you’re leaving TFLOP/s on the table.
2.3 The Roofline in One Sentence
Every kernel you write is either compute-bound (the MXU is the bottleneck and memory can keep up) or memory-bound (the MXU sits idle, starved for data from HBM).
The dividing line is the ridge point:
If your kernel’s arithmetic intensity (FLOPs per byte transferred) is above 240, you’re compute-bound. Below it, you’re memory-bound. Spoiler: most naive kernels — including naive attention — land deep in memory-bound territory.
2.4 Double Buffering and Pipelining
The speed gap between HBM and VMEM is enormous. Without pipelining, the MXU just sits there twiddling its thumbs during every DMA transfer:
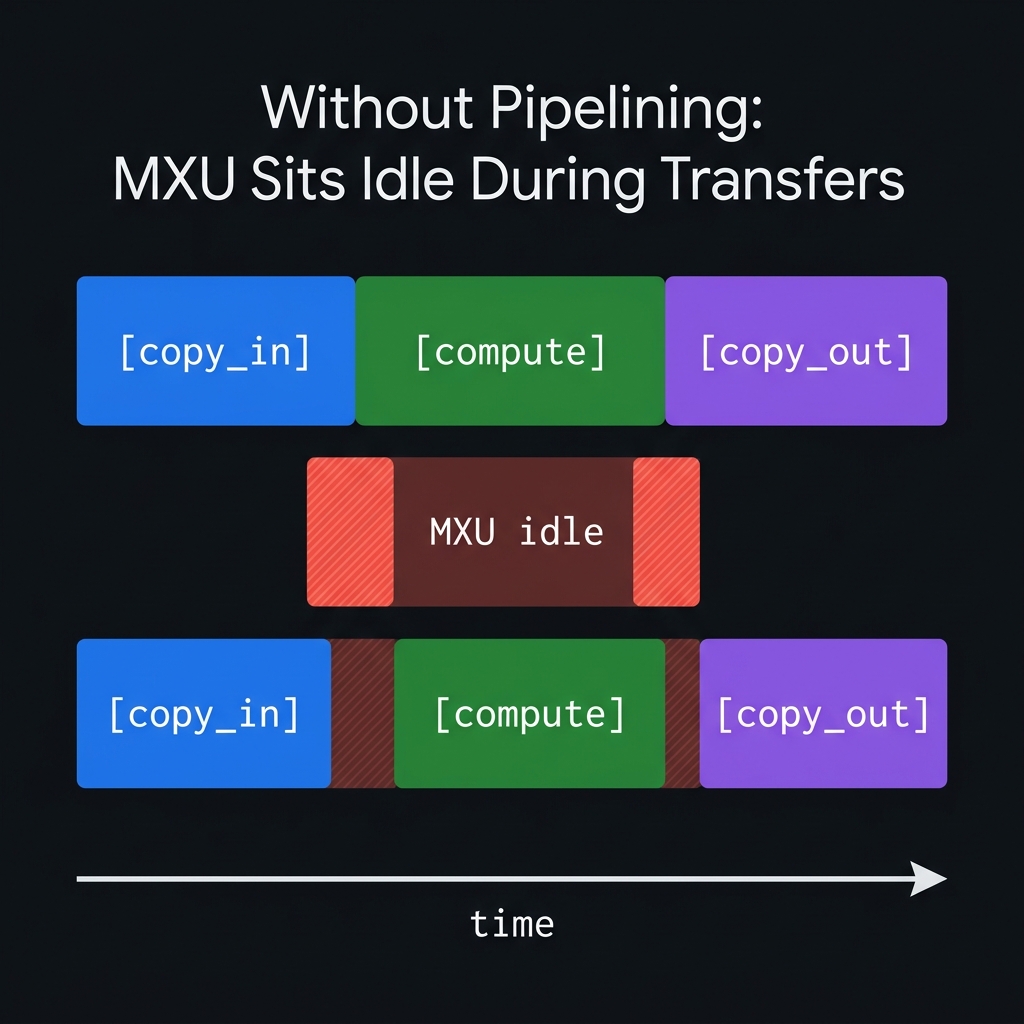
Pallas solves this with double buffering: while one buffer is being used for compute, the next iteration’s data is already being copied into a second buffer. In steady state, DMA and compute happen simultaneously:
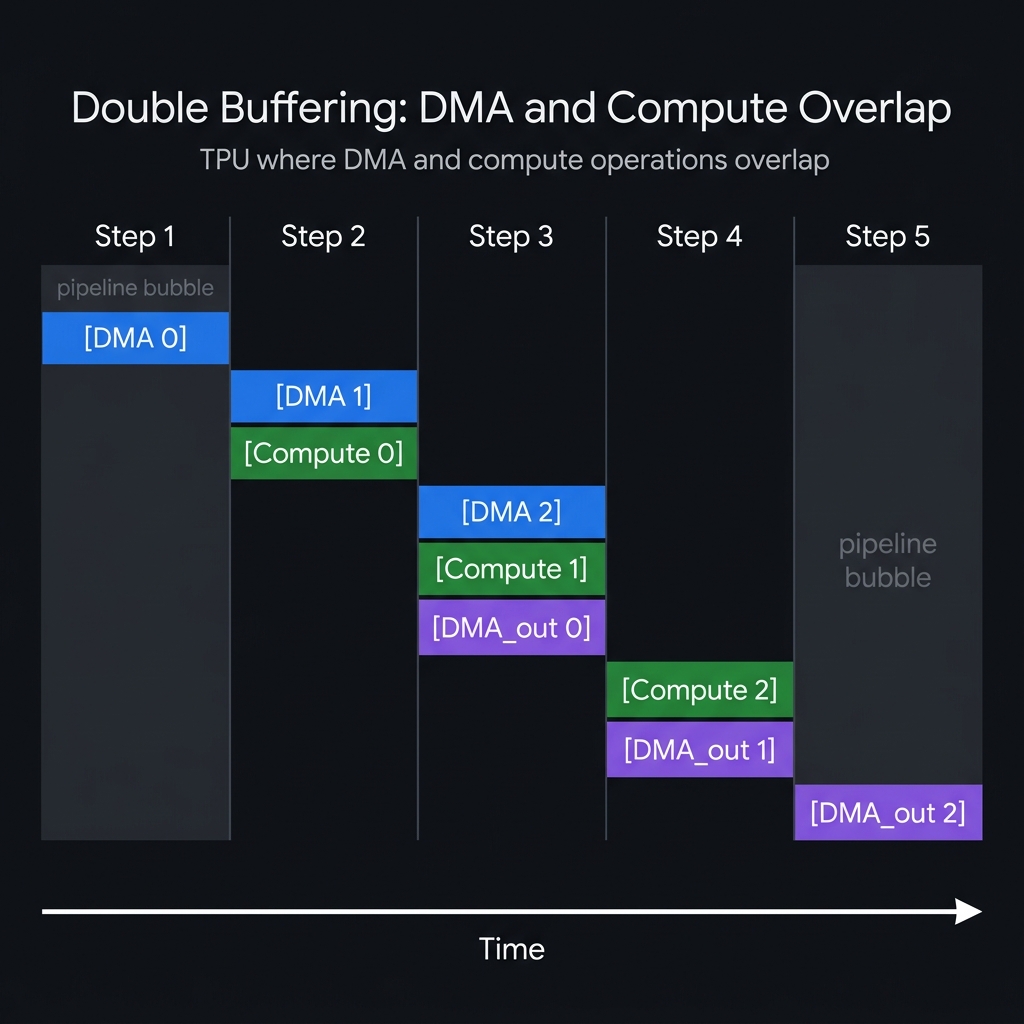
The first and last few steps — where not all pipeline stages are active — are called pipeline bubbles. More grid iterations mean a smaller bubble fraction, which means better efficiency.
3. The Pallas Programming Model
A Pallas kernel boils down to four primitives. Once you get these, everything else is just mixing and matching.
3.1 Refs (Not Arrays)
Your kernel function doesn’t receive JAX arrays. It receives Refs — pointers to buffers in VMEM. You explicitly read from and write to them:
def my_kernel(x_ref, y_ref, o_ref):
x = x_ref[...] # Read: VMEM → VREGs
y = y_ref[...] # Read: VMEM → VREGs
o_ref[...] = x + y # Write: VREGs → VMEM
Input refs are read-only; output refs are write-only (except during accumulation patterns, where you read-modify-write through scratch buffers — we’ll see this in action shortly).
3.2 The Grid
The grid parameter defines how many times your kernel function is invoked:
grid = (num_q_blocks, num_kv_blocks)
# Equivalent to:
# for i in range(num_q_blocks):
# for j in range(num_kv_blocks):
# kernel(...)
Here’s a critical difference from GPUs: grid iterations run sequentially in lexicographic order, not in parallel like GPU thread blocks. This might sound like a limitation, but it’s actually what makes accumulation patterns possible — you can keep a running accumulator in VMEM across iterations of the inner loop, and that’s exactly what FlashAttention needs.
3.3 BlockSpecs — Mapping Grid Indices to Memory Slices
A BlockSpec tells Pallas which slice of the full HBM tensor to load into VMEM for each grid iteration:
pl.BlockSpec(
block_shape=(BQ, HEAD_DIM), # Shape of each tile
index_map=lambda i, j: (i, 0) # Maps grid indices → block indices
)
The index_map returns block indices, not element indices. The element index is block_index × block_size. For attention, we want Q tiles indexed by i and K/V tiles indexed by j:
pl.BlockSpec((BQ, d), lambda i, j: (i, 0)) # Q: the i-th query chunk
pl.BlockSpec((BKV, d), lambda i, j: (j, 0)) # K: the j-th key chunk
pl.BlockSpec((BKV, d), lambda i, j: (j, 0)) # V: the j-th value chunk
3.4 Scratch Memory — State That Persists Across Iterations
This is where things get interesting. Scratch buffers live in VMEM and persist across grid iterations — unlike input/output buffers, they’re not double-buffered. That makes them perfect for accumulators and running statistics:
scratch_shapes=[
pltpu.VMEM((BQ, HEAD_DIM), jnp.float32), # acc — running output
pltpu.VMEM((BQ, HEAD_DIM), jnp.float32), # m — running row-max
pltpu.VMEM((BQ, HEAD_DIM), jnp.float32), # l — running row-sum
]
3.5 Putting It Together: pallas_call
result = pl.pallas_call(
kernel_fn, # Your kernel function
grid_spec=pltpu.PrefetchScalarGridSpec(
num_scalar_prefetch=0,
in_specs=[...], # BlockSpecs for inputs
out_specs=..., # BlockSpec for output
scratch_shapes=[...], # Persistent VMEM buffers
grid=(M, N), # Iteration space
),
out_shape=jax.ShapeDtypeStruct(...), # Output shape/dtype
compiler_params=pltpu.CompilerParams(
dimension_semantics=("parallel", "arbitrary"),
),
)(q, k, v)
The dimension_semantics argument tells the Mosaic compiler which grid dimensions have cross-iteration dependencies:
"parallel": No dependencies — can be split across cores on multi-core TPUs (v4, v5p)."arbitrary": Has dependencies (e.g., accumulation) — must run sequentially.
4. Naive Attention: The Starting Point
Before we get clever, let’s be clear about what we’re replacing. Here’s standard attention in plain JAX — nothing fancy:
def reference_fn(q, k, v):
d = q.shape[-1]
s = jnp.dot(q.astype(jnp.float32), k.astype(jnp.float32).T) / math.sqrt(d)
p = jax.nn.softmax(s, axis=-1)
return jnp.dot(p, v.astype(jnp.float32)).astype(jnp.bfloat16)
Five lines. Mathematically correct. Numerically stable (the softmax runs in f32). And catastrophically inefficient.
Why It’s Slow: The Memory Wall
At seq_len = 16,384 and head_dim = 128:
- Q @ K^T produces a
(16384, 16384)score matrix. In float32, that’s16384² × 4 bytes = 1.07 GB. - This entire matrix is written to HBM, then read back for the softmax.
- The softmax result
P(16384²values) is written to HBM again, then read back forP @ V. - Total HBM traffic for intermediates alone: ~3.2 GB of round-trips.
The FLOPs are dominated by two matmuls: Q @ K^T and P @ V, totaling approximately 4 × seq² × d ≈ 137 GFLOP. The arithmetic intensity comes out to roughly:
That’s 5.6× below the ridge point of 240 FLOPs/byte. The MXU is starving — it spends most of its time just waiting for data to bounce back and forth through HBM. What a waste.
5. The FlashAttention Algorithm: Online Softmax
The core idea behind FlashAttention (Dao et al., 2022) is deceptively simple: never materialize the full attention matrix. Instead of computing that giant $n \times n$ score matrix and dumping it to HBM, you process Q and K/V in small tiles — computing partial softmax results as you go and accumulating them with an online algorithm that tracks running statistics. Let’s see how.
5.1 Why Standard Softmax Needs Two Passes
The standard softmax formula for a row $x = [x_1, \ldots, x_n]$ is:
Computing this requires two passes over the data:
- Pass 1: Find the maximum $m$.
- Pass 2: Compute all $e^{x_j - m}$ and their sum.
For a full attention row, that means you need all $n$ score values before you can compute any softmax output. At $n = 16,384$, you’re forced to materialize the full row.
5.2 The Online Softmax Recurrence
The key observation is that you can update a partial softmax when new data arrives. Suppose you’ve processed KV blocks $1, \ldots, j{-}1$ and maintained:
- $m^{(j-1)}$: running maximum of all scores seen so far (scalar per query row)
- $l^{(j-1)}$: running sum of exponentials: $\sum_{i=1}^{(j-1) \cdot B_{KV}} e^{s_i - m^{(j-1)}}$
- $O_{\text{acc}}^{(j-1)}$: running output accumulator: $\sum_{i=1}^{(j-1) \cdot B_{KV}} e^{s_i - m^{(j-1)}} \cdot V_i$
When the next KV block $j$ arrives, the update rules are:
where $P^{(j)}_k = e^{S^{(j)}_k - m^{(j)}}$ are the unnormalized attention weights for block $j$.
At the end, after all KV blocks are processed:
5.3 Why This Works
The correction factor $\alpha$ rescales all previously accumulated values to account for the new maximum. This is mathematically exact — there’s no approximation happening here. The final answer is bit-for-bit identical to the standard softmax-attention formula.
And here’s the payoff: only a (BQ, BKV) tile of scores lives in VMEM at any time. The accumulator O_acc is (BQ, d) — proportional to the block size, not the sequence length. That O(n²) memory allocation we were complaining about? Gone entirely.
5.4 Mapping the Algorithm to the Kernel
Now let’s see how this math maps to actual Pallas code. Each kernel invocation processes one (q_block, kv_block) pair:
def attention_kernel(q_ref, k_ref, v_ref, o_ref, acc_ref, m_ref, l_ref, *, nsteps):
kv_step = pl.program_id(1)
# Initialize scratch on first KV step
@pl.when(kv_step == 0)
def _():
acc_ref[...] = jnp.zeros((bq, d), dtype=jnp.float32)
m_ref[...] = jnp.full((bq, d), float("-inf"), dtype=jnp.float32)
l_ref[...] = jnp.zeros((bq, d), dtype=jnp.float32)
# Load tiles from VMEM into registers
q = q_ref[...] # (BQ, d)
k = k_ref[...] # (BKV, d)
v = v_ref[...] # (BKV, d)
# --- S = Q @ K^T ---
s = lax.dot_general(q, k,
dimension_numbers=(((1,), (1,)), ((), ())),
preferred_element_type=jnp.float32) # (BQ, BKV) in f32
# --- Online softmax update ---
block_max = jnp.max(s, axis=1) # (BQ,)
m_prev = m_ref[:, 0] # (BQ,) — extract from scratch
m_new = jnp.maximum(m_prev, block_max) # (BQ,)
alpha = jnp.exp(m_prev - m_new) # correction factor
p = jnp.exp(s - m_new[:, None]) # (BQ, BKV) — unnormalized weights
l_new = alpha * l_ref[:, 0] + jnp.sum(p, axis=1)
# --- Accumulate: O_acc = alpha * O_acc + P @ V ---
pv = lax.dot_general(p.astype(jnp.bfloat16), v,
dimension_numbers=(((1,), (0,)), ((), ())),
preferred_element_type=jnp.float32) # (BQ, d) in f32
acc_ref[...] = alpha[:, None] * acc_ref[...] + pv
m_ref[...] = m_new[:, None] * jnp.ones((1, d), dtype=jnp.float32)
l_ref[...] = l_new[:, None] * jnp.ones((1, d), dtype=jnp.float32)
# --- Final normalization on last KV step ---
@pl.when(kv_step == nsteps - 1)
def _():
o_ref[...] = (acc_ref[...] / l_ref[:, 0][:, None]).astype(jnp.bfloat16)
This is a working FlashAttention kernel. It’s correct — you can verify it against the reference implementation and the outputs will match. But it has several deliberately naive choices that leave real performance on the table. Spotting those inefficiencies, and fixing them one by one, is what the rest of this article is about.
6. What Is Kernel Fusion?
Before we jump into specific optimizations, let’s nail down the concept that ties them all together: kernel fusion.
6.1 The Unfused World
In a standard JAX computation, each operation launches a separate kernel. For attention, here’s what actually happens under the hood:
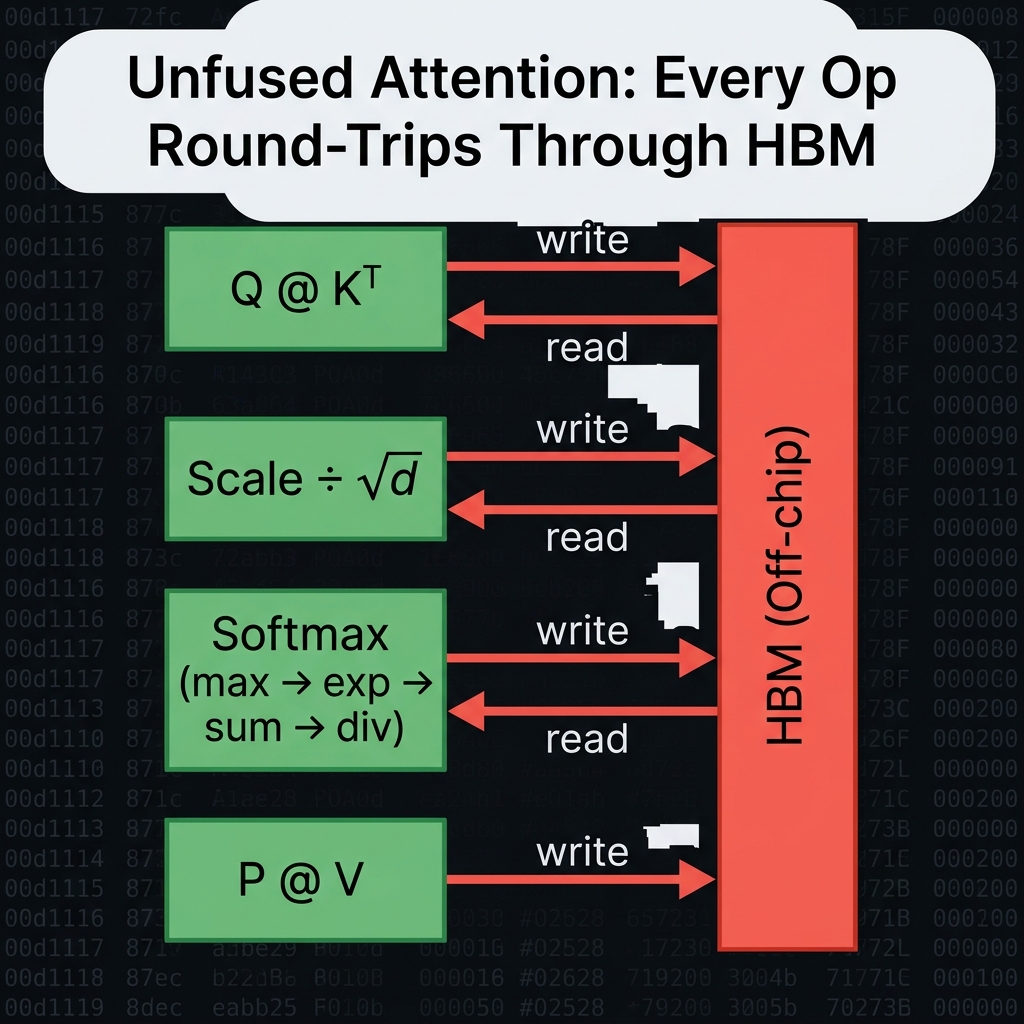
Every write → read round-trip through HBM is a bandwidth tax that delivers zero computational benefit. For elementwise operations like scaling and softmax, the compute cost is trivial compared to the memory traffic — they’re inherently memory-bound.
6.2 The Fused World
In a fused kernel, all of that happens in a single kernel launch. Intermediate values stay in VMEM or VREGs and never touch HBM until the final output:
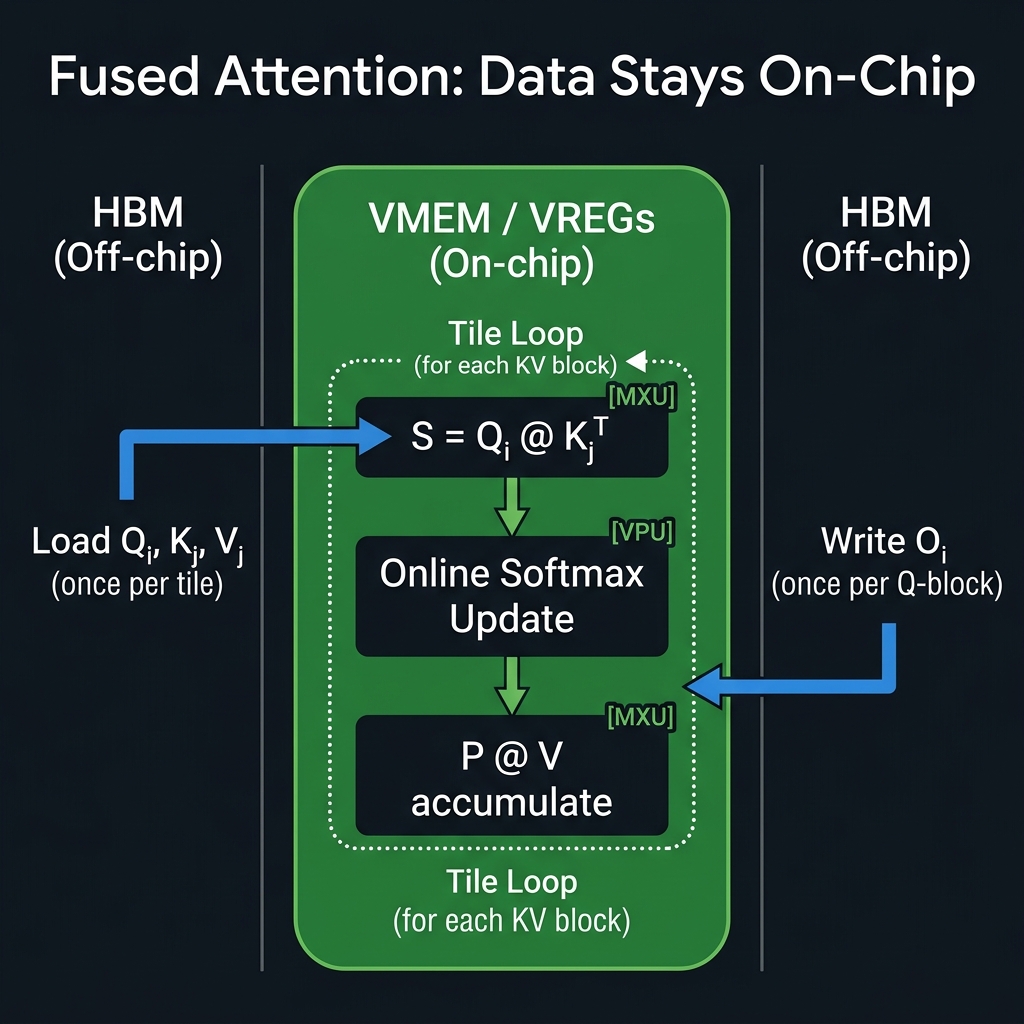
The total HBM traffic drops from O(n² × multiple round-trips) to O(n × d × small constant). That’s the fundamental win of fusion.
6.3 The Fusion Spectrum: Inner Loop vs. Outer Loop
Not all fused computations are equal. Operations that run inside the inner KV loop execute once per tile, while operations in the outer loop execute once per Q-block:
| Operation | Where it runs | Cost per Q-block |
|---|---|---|
| Scale Q by 1/√d | Outside the pallas_call (once total) | Free |
| Q @ K^T matmul | Inner loop (every KV step) | BQ × BKV × d MXU ops |
| exp(S − m) | Inner loop (every KV step) | BQ × BKV VPU ops |
| Row-wise max/sum | Inner loop (every KV step) | BQ × BKV VPU reductions |
| P @ V matmul | Inner loop (every KV step) | BQ × d × BKV MXU ops |
| Final O normalization | Inner loop (last KV step only) | BQ × d VPU ops |
The takeaway: anything you can hoist from the inner loop to the outer loop — or outside the kernel entirely — is essentially free performance.
7. Fusion Experiments
Alright, time for the fun part. Let’s run concrete experiments. Each fusion targets a specific inefficiency in the naive kernel, and we’ll measure the impact using the prepare.py benchmark harness.
Experiment A: Pre-Scale Q — Moving Invariant Work Outside the Loop
The Problem: In the naive kernel, the score matrix S needs to be scaled by $1/\sqrt{d}$. If this scaling is applied inside the inner loop, it costs BQ × BKV multiplications per KV step — and the same scale factor is applied identically every time.
The Fix: Move the scaling into the wrapper function, before the pallas_call:
def flash_attention(q, k, v, *, bq=BQ, bkv=BKV):
seq_len, d = q.shape
sm_scale = 1.0 / math.sqrt(d)
q = q * sm_scale # ← Scale once, outside the kernel
nsteps = seq_len // bkv
return pl.pallas_call(...)( q, k, v)
Inside the kernel, q_ref[...] now contains pre-scaled queries. The s *= scale line disappears entirely from the inner loop.
Why It Matters: With BQ=1024, BKV=512, and $d$=128, the kernel loop runs seq_len / BKV = 32 steps per Q-block. That’s 32 × 1024 × 512 = 16.7M redundant multiplies per Q-block. Across all 16 Q-blocks: roughly 268M wasted FLOPs. Not huge in absolute terms, but it’s literally free performance — you’re just moving one line of code.
Measured result (TPU v5 lite, seq=16384, d=128):
| Latency | TFLOP/s | Util | Speedup | |
|---|---|---|---|---|
| Pallas Naive | 2.26 ms | 60.8 | 30.9% | 2.08× |
| + Fusion A | 2.25 ms | 61.1 | 31.0% | 2.09× |
As expected: a marginal improvement — the scale op is genuinely cheap and XLA may have already been hoisting it. The real value is consistency: you’ve removed a correctness risk (accidentally re-scaling) and set up for the next fusions.
Experiment B: Precision Management — Let the MXU Do What It Does Best
The Problem: The naive kernel has several precision mistakes:
-
Q and K are bf16 tensors. The
lax.dot_generalwithpreferred_element_type=jnp.float32tells the MXU to accumulate in f32 — which is correct. But if the inputs are upcast to f32 before the dot, the MXU still truncates them to bf16 internally (it’s a bf16 × bf16 systolic array on v5e). The upcast wastes bandwidth for zero accuracy gain. -
V is similarly upcast to f32 unnecessarily before
P @ V. -
P (the softmax output, computed in f32) is cast to bf16 before the P @ V matmul. This discards softmax precision.
The Fix: Keep Q, K, V in their native bf16 and let preferred_element_type=jnp.float32 handle accumulation:
# Before (naive):
s = lax.dot_general(
q.astype(jnp.float32), # ← unnecessary upcast
k.astype(jnp.float32), # ← unnecessary upcast
..., preferred_element_type=jnp.float32)
# After (optimized):
s = lax.dot_general(
q, k, # ← keep as bf16
..., preferred_element_type=jnp.float32)
Why It Matters: Keeping Q and K in bf16 halves the bandwidth needed to load them from VMEM into VREGs for the matmul. The MXU natively processes bf16 inputs and accumulates in f32 — that’s literally what it was designed to do. Forcing f32 inputs buys you zero extra precision and costs double the memory traffic.
Measured result (TPU v5 lite, seq=16384, d=128):
| Latency | TFLOP/s | Util | Speedup | |
|---|---|---|---|---|
| Fusion A | 2.25 ms | 61.1 | 31.0% | 2.09× |
| + Fusion B | 2.25 ms | 61.2 | 31.0% | 2.09× |
Almost identical — the improvement is negligible at this tile size. That said, at larger block sizes or higher sequence lengths where VMEM→VREGs bandwidth becomes the bottleneck, this matters more. On v5e with BQ=1024 and BKV=512, we’re already mostly compute-bound on the matmuls, so shaving VMEM bandwidth isn’t the limiting factor here.
Experiment C: Compact Scratch Buffers — Eliminating 128× VMEM Waste
The Problem: The running maximum m and running sum l are scalars per query row — one value per row of the Q block. That’s BQ values each. But the naive kernel stores them as (BQ, HEAD_DIM) arrays with every column identical:
# Naive scratch shapes — 128× waste
pltpu.VMEM((BQ, HEAD_DIM), jnp.float32), # m: (1024, 128) = 512 KB
pltpu.VMEM((BQ, HEAD_DIM), jnp.float32), # l: (1024, 128) = 512 KB
At BQ=1024 and HEAD_DIM=128, each buffer is 1024 × 128 × 4 = 512 KB. The actual information content is 1024 × 4 = 4 KB — a 128× waste. This inflates both VMEM usage and the write traffic when updating m and l at every KV step.
The Fix: Store m and l as (BQ,) shaped scratch. Broadcast to (BQ, 1) only when needed for the rescale:
# Compact scratch shapes
pltpu.VMEM((BQ,), jnp.float32), # m: (1024,) = 4 KB
pltpu.VMEM((BQ,), jnp.float32), # l: (1024,) = 4 KB
And in the kernel body:
# Before:
m_ref[...] = m_new[:, None] * jnp.ones((1, d), dtype=jnp.float32) # broadcast write
# After:
m_ref[...] = m_new # direct scalar-per-row write
Why It Matters: This saves 1 MB of VMEM (from 1024 KB down to 8 KB for both m and l combined). More importantly, it eliminates 2 × BQ × HEAD_DIM × 4 bytes = 1 MB of VMEM writes per KV step. Over 32 KV steps per Q-block and 16 Q-blocks, that’s roughly 512 MB of wasted write traffic — gone.
Note: Whether
(BQ,)shaped scratch works depends on the Pallas compiler version and TPU generation. The VPU register tile shape is 8 × 128, and scalar-per-row buffers may need special handling. If the compiler rejects this shape, try(BQ, 1)— still a 128× improvement over the naive approach.
Measured result (TPU v5 lite, seq=16384, d=128):
| Latency | TFLOP/s | Util | Speedup | |
|---|---|---|---|---|
| Fusion A+B | 2.25 ms | 61.2 | 31.0% | 2.09× |
| + Fusion C | 2.71 ms | 50.7 | 25.7% | 1.73× |
Compact scratch made things slower on this hardware and JAX version. This is a real result and worth understanding. The (BQ,) shaped scratch forces the Mosaic compiler into a slower code path likely because the VPU’s native tile shape is 8 × 128, and a 1D scratch of shape (BQ,) doesn’t align naturally with that layout. The compiler may be inserting extra shape-cast operations or spilling. The fallback (BQ, 1) shape is worth trying as it stays 2D while still being 128× smaller than (BQ, HEAD_DIM). This is a good reminder that memory layout optimizations need empirical validation — the theory is sound but the compiler’s code-gen can surprise you.
8. The Full Fused Kernel
Putting all three fusions together, here’s what the final kernel looks like. Notice how each optimization from our experiments is reflected in the code:
BQ = 1024 # Query block size
BKV = 512 # Key/Value block size
def attention_kernel(q_ref, k_ref, v_ref, o_ref, acc_ref, m_ref, l_ref, *, nsteps):
kv_step = pl.program_id(1)
bq, d = q_ref.shape
@pl.when(kv_step == 0)
def _():
acc_ref[...] = jnp.zeros((bq, d), dtype=jnp.float32)
m_ref[...] = jnp.full((bq,), float("-inf"), dtype=jnp.float32)
l_ref[...] = jnp.zeros((bq,), dtype=jnp.float32)
# Q is already pre-scaled by 1/sqrt(d) in the wrapper [Fusion A]
q = q_ref[...] # bf16 — no upcast [Fusion B]
k = k_ref[...] # bf16 — no upcast [Fusion B]
v = v_ref[...] # bf16 — no upcast [Fusion B]
# S = Q_scaled @ K^T — bf16 inputs, f32 accumulation
s = lax.dot_general(q, k,
dimension_numbers=(((1,), (1,)), ((), ())),
preferred_element_type=jnp.float32)
# Online softmax update with compact scratch [Fusion C]
block_max = jnp.max(s, axis=1)
m_prev = m_ref[...]
m_new = jnp.maximum(m_prev, block_max)
alpha = jnp.exp(m_prev - m_new)
p = jnp.exp(s - m_new[:, None])
l_new = alpha * l_ref[...] + jnp.sum(p, axis=1)
# P @ V — P in bf16, accumulate in f32
pv = lax.dot_general(p.astype(jnp.bfloat16), v,
dimension_numbers=(((1,), (0,)), ((), ())),
preferred_element_type=jnp.float32)
acc_ref[...] = alpha[:, None] * acc_ref[...] + pv
m_ref[...] = m_new # compact write [Fusion C]
l_ref[...] = l_new # compact write [Fusion C]
@pl.when(kv_step == nsteps - 1)
def _():
o_ref[...] = (acc_ref[...] / l_ref[...][:, None]).astype(jnp.bfloat16)
@functools.partial(jax.jit, static_argnames=["bq", "bkv"])
def flash_attention(q, k, v, *, bq=BQ, bkv=BKV):
seq_len, d = q.shape
q = q * (1.0 / math.sqrt(d)) # Pre-scale outside the kernel [Fusion A]
nsteps = seq_len // bkv
return pl.pallas_call(
functools.partial(attention_kernel, nsteps=nsteps),
grid_spec=pltpu.PrefetchScalarGridSpec(
num_scalar_prefetch=0,
in_specs=[
pl.BlockSpec((bq, d), lambda i, j: (i, 0)),
pl.BlockSpec((bkv, d), lambda i, j: (j, 0)),
pl.BlockSpec((bkv, d), lambda i, j: (j, 0)),
],
out_specs=pl.BlockSpec((bq, d), lambda i, j: (i, 0)),
scratch_shapes=[
pltpu.VMEM((bq, d), jnp.float32), # acc
pltpu.VMEM((bq,), jnp.float32), # m — compact [Fusion C]
pltpu.VMEM((bq,), jnp.float32), # l — compact [Fusion C]
],
grid=(seq_len // bq, nsteps),
),
out_shape=jax.ShapeDtypeStruct((seq_len, d), jnp.bfloat16),
compiler_params=pltpu.CompilerParams(
dimension_semantics=("parallel", "arbitrary"),
),
)(q, k, v)
Benchmark results (JAX 0.10.0, TPU v5 lite, seq=16384, head_dim=128, BQ=1024, BKV=512):
| Kernel | Latency | TFLOP/s | MXU Util | Speedup vs. JAX | Max Error |
|---|---|---|---|---|---|
| Reference (naive JAX) | 4.70 ms | 29.3 | 14.9% | 1.00× | 0.000000 |
| Pallas Naive | 2.26 ms | 60.8 | 30.9% | 2.08× | 0.000488 |
| + Fusion A (pre-scale Q) | 2.25 ms | 61.1 | 31.0% | 2.09× | 0.000488 |
| + Fusion B (precision) | 2.25 ms | 61.2 | 31.0% | 2.09× | 0.000488 |
| Full Fused A+B+C (compact scratch) | 2.71 ms | 50.7 | 25.7% | 1.73× | 0.000488 |
Key takeaways from the numbers:
- The biggest win comes from moving to Pallas at all. Switching from naive JAX to even an unfused Pallas kernel gives a 2.08× speedup — the tiled, on-chip computation eliminates the O(n²) HBM round-trips.
- Fusions A and B are marginal here. At BQ=1024/BKV=512, we’re already fairly compute-bound on the matmuls. The scale op and precision fixes don’t move the needle significantly on this hardware configuration — they matter more at larger tile sizes or on memory-bandwidth-constrained hardware.
- Fusion C (compact scratch) causes a regression. The
(BQ,)shaped 1D scratch doesn’t align well with the VPU’s native8 × 128tile shape on this JAX/TPU version, and the compiler generates slower code. The(BQ, 1)fallback is the next thing to try — it stays 2D while still being 128× smaller than the naive(BQ, HEAD_DIM)layout. - Error of 0.000488 on all Pallas kernels vs. the reference is expected — it’s just bfloat16 rounding, not a correctness bug.
The error of 0.000488 for all Pallas variants is expected bfloat16 rounding, not a correctness issue.
9. Takeaways
What we built: A single-head FlashAttention kernel in Pallas that computes exact attention without ever writing the $n \times n$ score matrix to HBM. It tiles the computation into (BQ, BKV) blocks, uses the online softmax recurrence to track running statistics in VMEM scratch buffers, and fuses everything — scaling, matmuls, softmax, normalization — into one kernel launch.
What the numbers actually showed:
- The dominant win is moving to Pallas at all — 2.08× over naive JAX, from tiling alone eliminating the n² HBM traffic. The micro-fusions (A and B) were marginal on this hardware at these tile sizes because we’re already mostly compute-bound.
- Theory doesn’t always match practice. Fusion C (compact scratch) regressed on this JAX 0.10.0/TPU v5 lite configuration. The 1D
(BQ,)scratch shape doesn’t align with the VPU’s 8×128 native tile, causing the compiler to generate less efficient code. The(BQ, 1)shape is the next experiment. - Benchmarking matters. Without measuring each step individually, you’d never know which fusion actually helped and which hurt. Intuition about memory saves doesn’t always translate to wall-clock wins.
What’s next: We have a working kernel, real numbers, and one open question (the compact scratch regression). Article 2 digs into why: reading the roofline, interpreting the HLO, and using XProf traces to diagnose exactly where the cycles are going.
Glossary
| Term | Definition |
|---|---|
| HBM | High Bandwidth Memory. Off-chip DRAM, ~819 GB/s on v5e. Where full tensors live. |
| VMEM | Vector Memory. On-chip SRAM scratchpad, 128 MiB on v5e. Where Pallas tiles live during compute. |
| VREGs | Vector Registers. 8 sublanes × 128 lanes. Where computation happens. |
| MXU | Matrix Multiply Unit. 128×128 systolic array. Peak: 197 TFLOP/s (bf16) on v5e. |
| VPU | Vector Processing Unit. Elementwise operations. |
| Ridge Point | Arithmetic intensity threshold (~240 FLOPs/byte on v5e) separating memory-bound from compute-bound. |
| BQ, BKV | Block sizes for query and key/value tiles along the sequence dimension. |
| Pallas | JAX’s kernel-authoring extension for writing custom accelerator kernels. |
| FlashAttention | Tiled, IO-aware attention algorithm (Dao et al., 2022) using online softmax. |
| Fusion | Combining multiple operations into a single kernel launch to avoid intermediate HBM round-trips. |
References
- Dao, T., Fu, D.Y., Ermon, S., Rudra, A., & Ré, C. (2022). FlashAttention: Fast and Memory-Efficient Exact Attention with IO-Awareness. NeurIPS.
- Jouppi, N.P., et al. (2023). TPU v4: An Optically Reconfigurable Supercomputer for Machine Learning with Hardware Support for Embeddings. ISCA.
- JAX Team. Pallas: A JAX Kernel Language. https://jax.readthedocs.io/en/latest/pallas/
- Milakov, M. & Gimelshein, N. (2018). Online normalizer calculation for softmax. arXiv:1805.02867.


